- Document your process or strategy.
- Have a solid base of unit tests.
- Don’t skimp on integration testing.
- Perform end-to-end testing for Critical User Journeys.
- Understand and implement the other tiers of testing.
- Understand your coverage of code and functionality.
- Use feedback from the field to improve your process.
Document your process or strategy
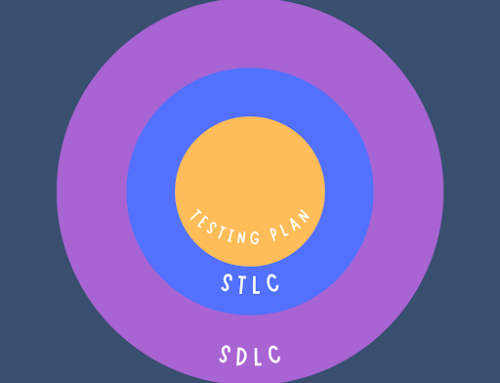
If you are already testing your product, document the entire process. This is essential for being able to both repeat the test for a later release and to analyze it for further improvement. If this is your first release, it’s a good idea to have a written test plan or strategy. In fact, having a written test plan or strategy is something that should accompany any product design.
Have a solid base of unit tests
A great place to start is writing unit tests that accompany the code. Unit tests test the code as it is written at the functional unit level. Dependencies on external services are either mocked or faked.
Don’t skimp on integration testing
Perform end-to-end testing for Critical User Journeys
The discussion thus far covers testing the product at its component level, first as individual components (unit-testing), then as groups of components and dependencies (integration testing). Now it’s time to test the product end to end as a user would use it. This is quite important because it’s not just independent features that should be tested but entire workflows incorporating a variety of features. At Google these workflows – the combination of a critical goal and the journey of tasks a user undertakes to achieve that goal – are called Critical User Journeys (CUJs). Understanding CUJs, documenting them, and then verifying them using end-to-end testing (hopefully in an automated fashion) complete the Testing Pyramid.
Understand and implement the other tiers of testing
Unit, integration, and end-to-end testing address the functional level of your product. It is important to understand the other tiers of testing, including:
- Performance testing – Measuring the latency or throughput of your application or service.
- Load and scalability testing – Testing your application or service under higher and higher load.
- Fault-tolerance testing – Testing your application’s behavior as different dependencies either fail or go down entirely.
- Security testing – Testing for known vulnerabilities in your service or application.
- Accessibility testing – Making sure the product is accessible and usable for everyone, including people with a wide range of disabilities.
- Localization testing – Making sure the product can be used in a particular language or region.
- Globalization testing – Making sure the product can be used by people all over the world.
- Privacy testing – Assessing and mitigating privacy risks in the product.
- Usability testing – Testing for user-friendliness.
Understand your coverage of code and functionality
So far, the question of how much testing is enough, from a qualitative perspective, has been examined. Different types of tests were reviewed and the argument made that smaller and earlier is better than larger or later. Now the problem will be examined from a quantitative perspective, taking code coverage techniques into account.
| Language | Tool |
|---|---|
| Java | JaCoCo |
| Java | JCov |
| Java | OpenClover |
| Python | Coverage.py |
| C++ | Bullseye |
| Go | Built in coverage support (go -cover) |
Use feedback from the field to improve your process
A very important part of understanding and improving your qualification process is the feedback received from the field once the software has been released. Having a process that tracks outages and bugs and other issues, in the form of action items to improve qualification, is critical for minimizing the risks of regressions in subsequent releases. Moreover, the action items should be such that they (1) emphasize filling the testing gap as early as possible in the qualification process and (2) address strategic issues such as the lack of testing of a particular type such as load or fault tolerance testing. And again, this is why it is important to document your qualification process so that you can reevaluate it in light of the data you obtain from the field.
Summary
Creating a comprehensive qualification process and testing strategy to answer the question “How much testing is enough?” can be a complex task. Hopefully the tips given here can help you with this. In summary:
- Document your process or strategy.
- Have a solid base of unit tests.
- Don’t skimp on integration testing.
- Perform end-to-end testing for Critical User Journeys.
- Understand and implement the other tiers of testing.
- Understand your coverage of code and functionality.
- Use feedback from the field to improve your process.
By George Pirocanac
Source: https://testing.googleblog.com/2021/06/how-much-testing-is-enough.html

{kind=link}