
Test automation architecture is the structural design that governs how automated tests are organized, executed, maintained, and connected to your delivery pipeline. It covers which layers of the system you test, how tests are parallelized, who owns what, how environments are managed, and how quality signals reach the people making deployment decisions.
It is not your framework. Playwright is a tool. Architecture is the set of decisions that determines how that tool — and everything around it — holds together when your team doubles and your test count triples.
It is also not your test strategy. Strategy answers what to test. Architecture answers how that testing physically works at scale.
You can have both a clear strategy and a capable framework and still end up with a suite that nobody trusts — because the architectural layer was never thought through. That’s the gap most teams fall into, and it’s more common than anyone in a sprint retrospective wants to admit.
Why Do Most Test Automation Architectures Fail?
Most test automation architectures fail not because of the tools chosen, but because no deliberate structural decisions were made as the suite grew. The failure doesn’t look like failure at first. It looks like success.
A small, sharp team builds a test suite that works. It catches bugs. It gives the team confidence. Leadership notices and scales the investment. More engineers write more tests — except now there’s no shared standard for how tests should be structured, no clear ownership, no policy on flakiness, and a staging environment that three teams are simultaneously depending on. Six months later you have 3,000 tests, a 40-minute CI pipeline, and a pass rate that everyone silently adds a mental asterisk to.
The specific patterns show up repeatedly across teams of every size. UI end-to-end tests everywhere — because those are the ones product managers understand — even when the same logic is already covered cheaper at the unit layer. Shared staging environments that make true parallelism impossible and turn every flaky failure into a debugging session that crosses team boundaries. Automatic retries that mask flakiness rather than surfacing it, until the suite is technically green but practically meaningless. No formal ownership model, so when tests break and nobody’s sure whose problem they are, they stay broken.
Each of these is solvable. None of them get solved by switching tools.
What Are the Core Principles of Scalable Test Automation Architecture?
Scalable test automation architecture rests on five design principles: layered validation, deliberate parallelism, environment isolation, built-in observability, and enforced governance. Each one compounds the others — and skipping any one of them is where the debt starts accumulating.
Layered Validation
Not just the test pyramid as a poster on a wall, but a genuine enforced distribution of test types. Unit tests cover isolated logic — fast, deterministic, high volume. Component and API tests validate service behavior and boundaries, and contract tests in particular are consistently the highest-ROI investment in microservice architectures. UI end-to-end tests validate critical user journeys and nothing more.
E2E tests are expensive. They should be treated like a scarce resource, not a first resort. The moment your E2E tests exceed 10–15% of your total suite, you should be asking hard questions about what those tests are proving that cheaper tests aren’t already proving.
Parallelism and Sharding as Design Decisions
Most teams bolt parallelism on after the fact and wonder why it doesn’t work cleanly. Worker parallelism runs multiple tests on one machine — right for medium-scale suites. Distributed sharding splits the suite across machines — necessary once single-machine parallelism can’t hit your target feedback window.
Runtime balancing allocates tests to shards based on historical execution time. Without it, your shards finish unevenly and your pipeline is only as fast as the slowest one. Critical path prioritization means your highest-risk tests run first, so a deployment decision can be made before the full suite finishes.
Environment Isolation
Shared environments are the single biggest source of flakiness in most mature suites. Ephemeral environments — spun up for a run, destroyed afterward — eliminate shared state by definition. Yes, they have an infrastructure cost. That cost is almost always lower than the engineering hours lost to intermittent failures and cross-team debugging. Every test should also own its data — creating what it needs on setup, cleaning it up on teardown. Any test that depends on pre-existing state is a future flaky test waiting to be discovered.
Observability
A test failing is an event. A test failing with traces, logs, screenshots, and a categorized failure type is a diagnosed event. The difference is the hours it takes to fix it.
Failure taxonomy matters — assertion failure, infrastructure failure, timeout, flake — because treating every failure identically makes prioritization impossible. Flake governance is a formal policy, not a cultural suggestion. Any test that fails without a code change and can’t be reproduced deterministically gets quarantined and tracked. Tests exceeding your defined flake threshold stay off the critical path until resolved.
Governance
Governance is how your architectural decisions survive the reality of growing teams and shipping pressure. Tagging standards so tests can be filtered by owner, risk tier, and execution context. CODEOWNERS files so test changes require sign-off from the accountable team. Linting rules that automatically flag anti-patterns — arbitrary waits, hardcoded environment values, missing teardown — before they reach the suite. Governance enforced by tooling survives. Governance enforced by asking nicely doesn’t.
What Does a 2026 Test Automation Reference Architecture Look Like?
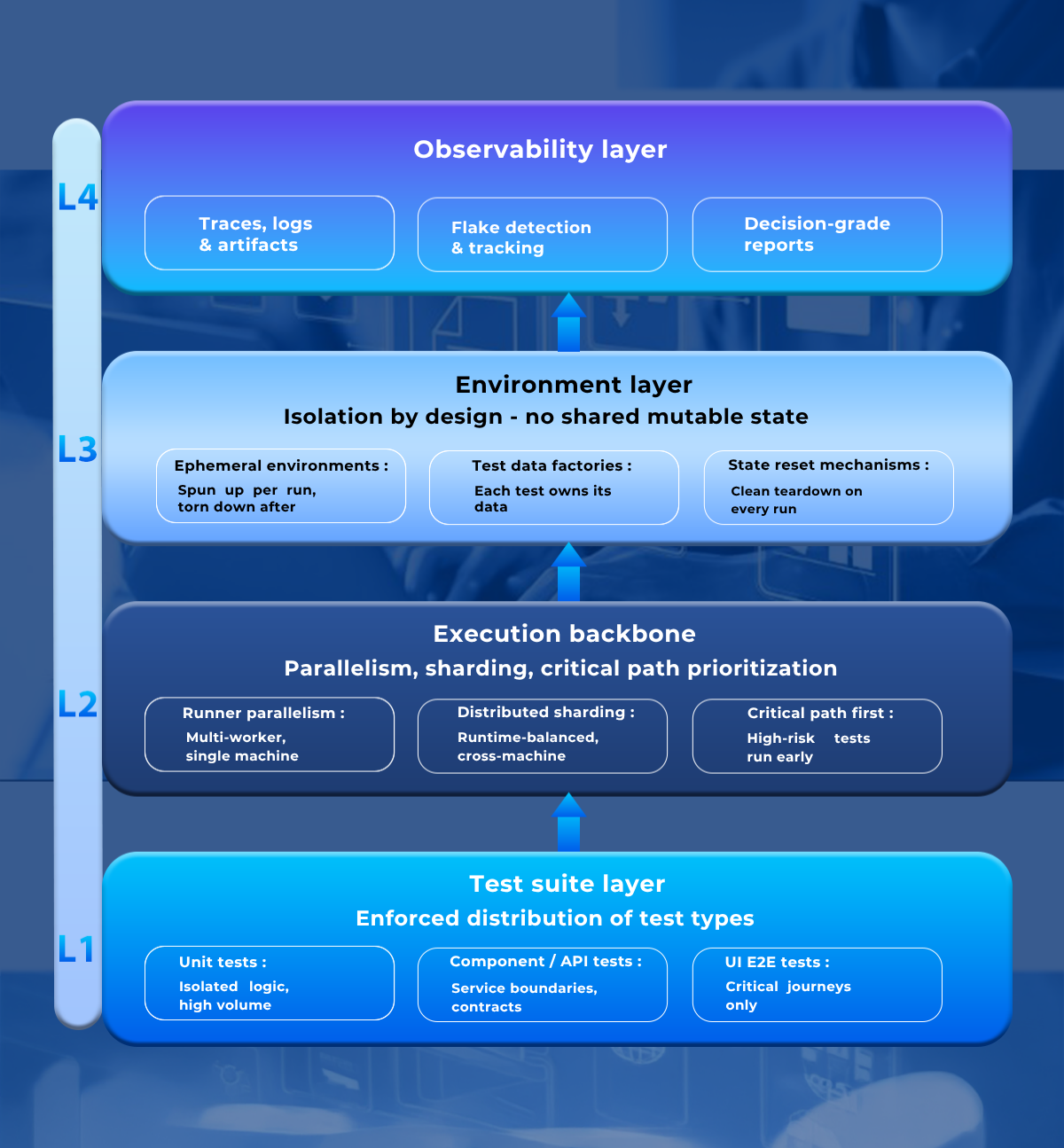
A modern test automation architecture in 2026 has four distinct layers: the test suite layer, the execution backbone, the environment layer, and the observability layer — each designed deliberately, not assembled by accident.
The test suite layer separates unit, component/API, and UI E2E tests with an enforced distribution. The execution backbone handles runner-native parallelism or grid-based execution with runtime shard balancing. The environment layer provisions ephemeral environments per run with test data factories and state reset mechanisms. The observability layer captures traces, logs, and artifacts, detects flakes, and surfaces decision-grade reports — not test counts.
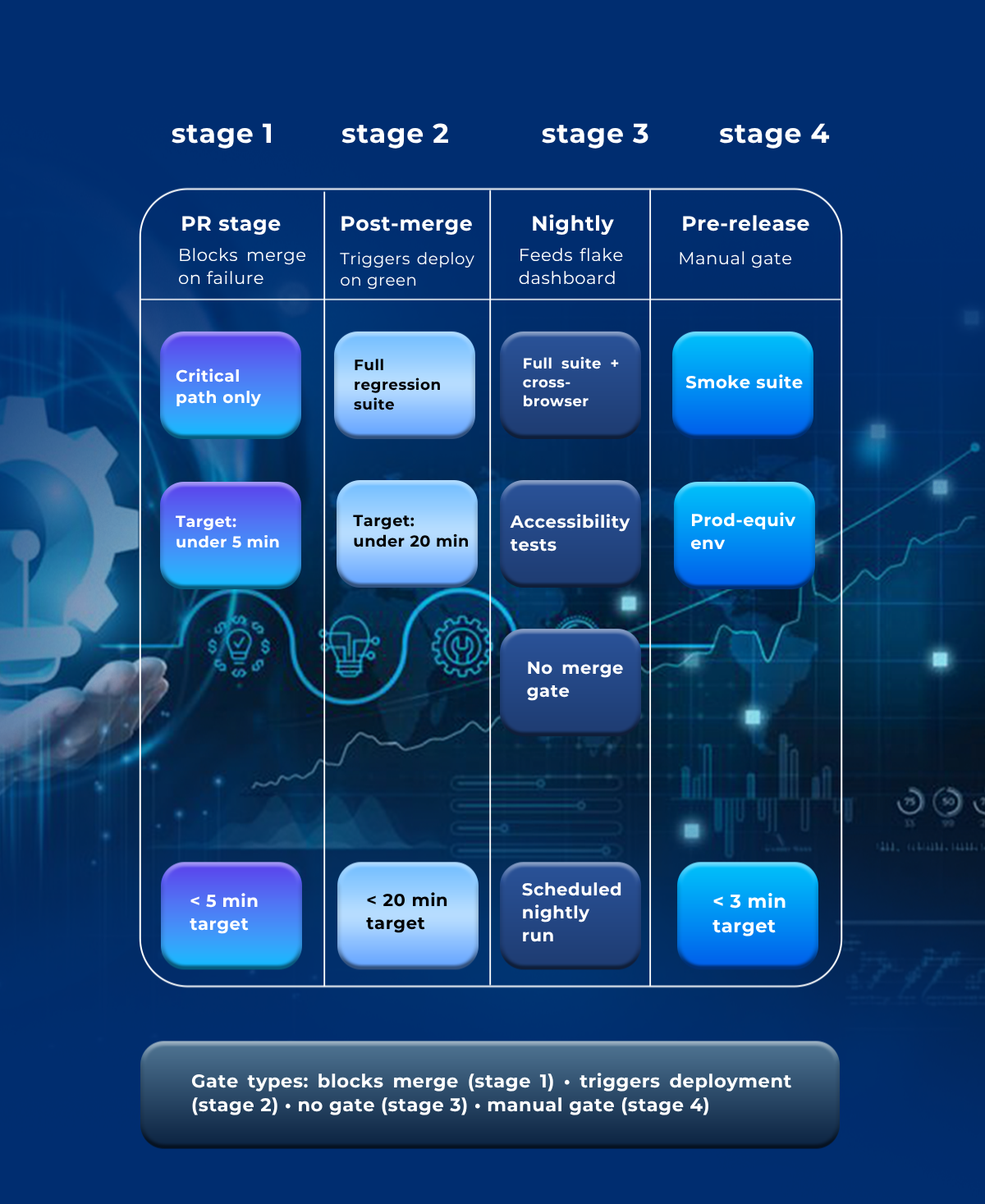
CI pipeline stages follow four tiers:
PR stage — critical path tests only, target under 5 minutes, blocks merge on failure.
Post-merge — full regression suite, target under 20 minutes, triggers deployment on green.
Nightly — full suite including cross-browser matrix and accessibility tests, no merge gate, feeds the flake tracking dashboard.
Pre-release — smoke suite against a production-equivalent environment, target under 3 minutes, manual gate.
On ownership: platform teams own the execution backbone, shared libraries, and standards. Embedded QA within product squads own their feature area — fully, with real accountability. The model where one centralized QA team owns everything produces a bottleneck and a suite that product engineers feel no responsibility toward. It’s the most common model and one of the most reliably dysfunctional ones.
What Are the Most Common Test Automation Anti-Patterns?
The most damaging test automation anti-patterns are: over-reliance on UI E2E tests, using retries to mask flakiness, centralized QA ownership, shared staging environments, and indefinitely deferred maintenance.
“Everything is E2E” — require every new E2E test to be justified against a risk assessment. If the scenario is already covered by unit or API tests, the E2E gets rejected.
“Retries will fix it” — retries mask failures, they don’t resolve them. One retry is acceptable. Automatic multi-retry is a signal that governance has already failed.
“One QA team owns everything” — distribute ownership to feature teams. A platform QA function maintains infrastructure and standards. Embedded QA within squads owns their area.
“Shared staging is good enough” — it isn’t, at scale. Design for environment isolation from the beginning.
“We’ll clean it up later” — the release cycle never ends. Allocate a defined percentage of each sprint to test maintenance. Track debt metrics on the same dashboard as delivery metrics.
How Do You Evolve an Existing Automation Architecture Without Breaking Delivery?
The key to evolving an existing test automation architecture is incremental, measured change run in parallel with delivery — never as a separate initiative.
At 100 tests, your only job is establishing conventions you won’t regret at 10,000. Layer model, naming, CI structure, ownership. Write it down. That document will save months of cleanup later.
At 1,000 tests, introduce parallelism, audit your E2E ratio, and start measuring flake rate. Assign ownership explicitly before it becomes political.
At 10,000 tests, your problems are active. Fix environment isolation first — it’s the primary source of instability at this scale. Then shard balancing. Then run a cost audit and remove the tests that aren’t catching anything. Systematic audits typically find 15–25% of tests in mature suites are redundant, obsolete, or low-signal.
Governance fails when it’s imposed. Involve the engineers who will be governed in designing the rules. Document the rationale behind every standard. Build trust through demonstrated value before expanding scope.
Frequently Asked Questions
How many UI end-to-end tests are too many? When UI end-to-end tests take longer than 15 minutes to return CI results, coverage has outpaced utility. Most mature teams cap UI tests at 5–10% of total suite volume, relying on API and contract tests to carry the bulk of regression coverage. A secondary signal: if UI test maintenance is consuming more engineering time than UI feature development, the ratio has inverted and needs correction.
When does a test automation suite need a dedicated execution grid? A grid becomes necessary when parallel execution requirements exceed what a single runner pool can handle — typically when running cross-browser matrix testing at scale, suites exceeding 2,000 UI tests, or when runner provisioning time is exceeding test execution time. Cloud grids are the lowest-friction entry point. Self-hosted grids make sense when data residency or volume economics require it.
Should tests be sharded by runtime or by risk? Start with runtime-based sharding to achieve even worker utilization and predictable CI duration. Layer risk-based prioritization on top so critical path tests run first regardless of shard assignment. Pure risk-based sharding without runtime data creates unbalanced workers. Pure runtime sharding without risk prioritization may delay signal on high-impact failures. The combination of both is the mature approach.
How do you measure test automation ROI? Track defect escape rate before and after automation investment, CI cycle time reduction, and manual regression hours recaptured per release. Avoid measuring by test count alone — 10,000 low-signal tests generate negative ROI through maintenance overhead and CI compute cost. A smaller suite with a measurably lower defect escape rate is the actual target state.
How do you reduce test flakiness long-term? Three structural changes: eliminate shared mutable state in test environments, enforce deterministic test data setup and teardown so every test owns its data, and institute a formal flake budget that quarantines tests exceeding a defined failure rate threshold rather than masking them with retries. Flake rate should live on the same dashboard as pass rate and be treated with the same seriousness.
What is the difference between test automation architecture and a test framework? A test framework is a tool — Playwright, pytest, TestNG. Test automation architecture is the system of decisions governing how that tool, and everything around it, is organized, executed, owned, and maintained at scale. You can change frameworks without changing your architecture. And you can have an excellent framework with a broken architecture, which is exactly the situation most struggling teams are in.

{kind=link}